Предыдущие две части были посвящены тому, как устроена система SIEM и зачем интегрировать ее со сканером уязвимостей. В них я рассказывала о корреляционных механизмах — неотъемлемой части функциональных способностей SIEM. Без корреляции событий SIEM превращается в простой «логгер», что попросту делает нерентабельным внедрение этого дорогостоящего решения. Постараюсь изложить материал как можно проще, чтобы поняли все, вне зависимости от квалификации. Поэтому не обращайте внимания на нарочно допущенные небольшие ляпы :)
Автор: Олеся Шелестова, исследовательский центр Positive Research
Для лог-менеджмента мне syslog достаточно (А. Лукацкий)
Предыдущие две части были посвящены тому, как устроена система SIEM и зачем интегрировать ее со сканером уязвимостей. В них я рассказывала о корреляционных механизмах — неотъемлемой части функциональных способностей SIEM. Без корреляции событий SIEM превращается в простой «логгер», что попросту делает нерентабельным внедрение этого дорогостоящего решения. Постараюсь изложить материал как можно проще, чтобы поняли все, вне зависимости от квалификации. Поэтому не обращайте внимания на нарочно допущенные небольшие ляпы :)
Предположим, что вы «сами с усами», оценили риски, в соответствии с угрозами и рисками установили SIEM, настроили сбор событий от активов своей организации без привлечения вендора, — и события потихоньку «побежали» на ваш сервер. Вы не сможете откинуться на спинку кресла и работать с одними только важными инцидентами. Это миф. Потому что далеко не во всех SIEM существуют предустановленные правила и корреляции, которые помогут определять угрозы. Правила корреляции, которые вам загрузит интегратор, будут слишком общими. Да, часть угроз вы сможете обнаруживать: на панели системы появятся более-менее красивые графики, будет чем порадовать руководство на презентации. Кроме того, часть времени вы сэкономите на консолидации журналов событий. Но на этом все. Что же делать дальше? Мы же хотим использовать SIEM на полную катушку! Ответ: настраивать корреляционные механизмы для выявления угроз и автоматизации процессов. Сразу стоит предупредить, что для этого нужен выделенный сотрудник и он должен действовать в рамках зацикленной модели PDCA.
Руководству не стоит в данном случае экономить, ведь новый сотрудник (или несколько, в зависимости от задач и объема информации) выявит угрозы в вашей инфраструктуре, минимизирует MTTR, обеспечит возможность непрерывно вести бизнес без финансовых потерь. Конечно, лучше это поручить экспертам, но все же давайте попробуем самостоятельно разобраться, что же такое корреляция, какая она бывает и как работает.
Существуют сигнатурные (rule based) и бессигнатурные методы корреляции. Сигнатурные — те, в которые человек должен добавить некие правила определения инцидентов (аналог систем обнаружения вторжения). Бессигнатурные — черный ящик, который сам отличает хорошее от плохого (этому его учат вендоры); естественно, что таким методом вы управлять практически не можете.
На бумаге методов существует великое множество, однако на практике применяются лишь следующие основные.
- Statistical — сложный бессигнатурный метод корреляции событий, основанный на измерении двух или более переменных и вычислении степени статистической связи между ними.
- RBR Rule-based (pattern based) (HP ECS, IMPACT, RuleCore) — метод, в котором взаимосвязи между событиями определяются аналитиками в заранее заданных специфических правилах.
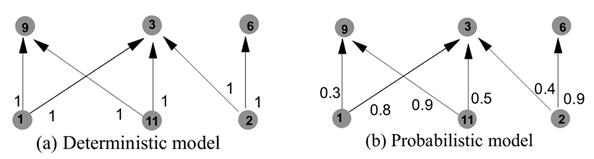
- CBR Codebook (case) based (SMARTS). Корреляция производится по подходящим векторам из предварительно заданной матрицы событий.
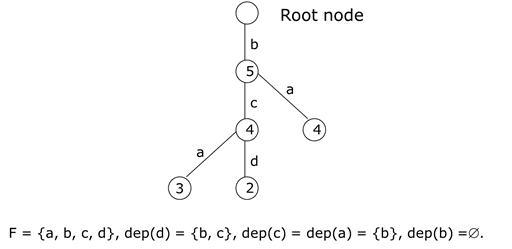
- MBR model based reasoning (слишком большой MTTR) — метод основан на абстракции объектов и наблюдения за ними в рамках модели.
- Bayesian (BDR) — это, надо полагать, всем известный метод, не требующий особых разъяснений. На практике — не эффективен.
- NMBR — Normalized model based reasoning. Схож с MBR, известен как baseline.
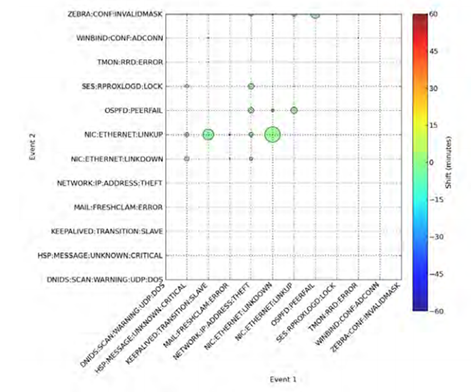
- Graph based. Корреляция заключается в поиске зависимостей между системными компонентами в графическом представлении (network devices, hosts, services) и построении графа на их основе. Если зависимость обнаруживается, граф используется для поиска основной причины возникновения проблемы (10 "HTTP server not responding” событий из-за отсутствия сетевого линка
- Neural network based — идеологический метод. Нейронная сеть обучается для обнаружения аномалий в потоке событий.
Как правило, в одном решении используется один или два метода корреляции. Важно не путать корреляцию с лжекорреляцией — с выводом на экран или в отчет однотипных событий или событий заданного класса. Пример: «failed access for last 24 hour».
Существует ошибочное мнение, будто технологии продвинулись настолько, что алгоритм может без участия человека «отличать хорошее от плохого», а сигнатурные методы имеют очень много ложных срабатываний. Да, срабатываний много: если система не настроена под вашу инфраструктуру и ваши задачи. Однажды на форуме Symantec один персонаж попросил меня разъяснить на пальцах — как включить автоматическую регистрацию инцидентов по заранее заданным правилам. Я объяснила, и на следующий день он спрашивал, как ему удалить несколько десятков тысяч инцидентов.
Вендоры SIEM постоянно возвращаются к сигнатурным методам, поскольку они гибче, имеют большую эффективность при обнаружении угроз, низкий MTTR.
Как же работают сигнатурные методы. Опустим нормализацию событий (приведение их к общему формату) с ее проблемами и примем за аксиому, что все события имеют одинаковый формат. Разберемся в теории.
В теории порождаемый инцидент (или угроза) — это «проблема» (мы не касаемся инцидент-менеджмента, где проблемами называют часто возникающие однотипные инциденты). У проблемы (problem, P) есть причина (cause, C). Это действительно даже при анализе рисков. Но в нашем случае поступающие события повествуют о возникшей или возникающей проблеме, т. е. являются симптомами (symptoms, S).
Выяснение причин — трудная, но решаемая задача. Крайне ограниченное количество существующих на рынке SIEM могут определить причину инцидента.
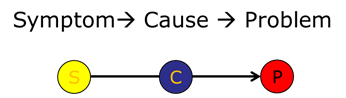
В большинстве случаев выявление причины необходимо для адекватной реакции на инцидент или осуществляется в контексте инцидента (например, пользователь изменил параметры запуска демона, причину предстоит выяснить). Вендоров, использующих накопленную базу знаний для выявления или корреляции причин инцидента, можно пересчитать по пальцам одной руки.
Вторжению в вашу инфраструктуру предшествуют различные события: сканирования, пусть даже растянутые во времени, попытки установить соединение по закрытым портам, блокирование вложений на почтовом сервере, появление учетной записи с повышенными привилегиями... Все это симптомы. Правило объединяет симптомы, приводящие к возникновению инцидента (к проблеме, Problem).
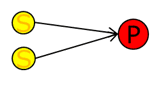
К одной проблеме могут приводить один или несколько симптомов, которые возникают в результате события. Из одного события зачастую можно получить несколько симптомов. Симптомы одной проблемы могут быть как составные, так и взаимоисключающие.
Один и тот же симптом может приводить к одной или нескольким проблемам. При этом могут существовать вероятностные (probabilistic model) связи между проблемой и симптомом. Эти связи лучше поручить экспертам J В этом случае, естественно, фиксируется только одна проблема, имеющая максимальный (или превышающий определенное установленное значение) вес (вероятность) со максимальным количеством обнаруженных симптомов.
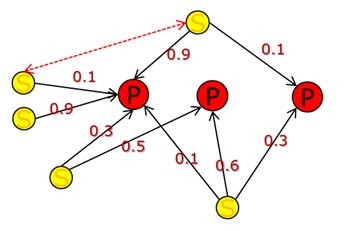
Приведу пример вероятностной связи. В системном журнале Microsoft Windows есть событие «Тип запуска службы "Служба Сервер(LanmanServer)" был изменен с "Автоматически" на "Отключена"». Симптом здесь — изменение параметра запуска службы. Этот симптом при отсутствии уточнений может привести к одной из следующих проблем.
- «Уязвимость», если служба запущена и содержит уязвимости, то это может привести к несанкционированному доступу, такая служба не должна быть запущена, или риски минимизированы, т.е. служба заранее остановлена.
- «Нарушение стабильности OS», остановка части служб может привести к BSOD или к проблемам загрузки.
- «Нарушение политик», если изменение параметров запуска службы разрешено только определенным администраторам или служба должна находиться в определенном состоянии. Запуск от имени пользователя в данном случае является вторым симптомом.
В данном примере будет зафиксирована только одна проблема — с максимальной вероятностью при наличии всех симптомов. Это простейший случай configuration/policy/compliance management (в зависимости от задач) для SIEM. Описав необходимое правило корреляции, мы можем легко контролировать, например, службы антивирусного ПО (и его наличие) на IТ-активах в нашей сети. Обнаружение подобных единичных симптомов бессигнатурными методами корреляции затруднено. Например, метод graph based сможет их обнаружить, если возникнет событие, связанное со сбоем соединения между какой-либо службой и активом. Метод NMBR обнаружит только массовое изменение состояния сервисов (очевидно, что это – единичные случаи).
Симптомы без проблем — это одно или несколько простейших событий в SIEM. Симптомы без проблем могут быть объединены в классы, например класс «Нарушение политики доступа» (Policy login violation). По такому классу можно выбрать события, но корреляция по ним может не производиться, если нет специального правила.
Идея сигнатурного метода, как вы уже, очевидно, поняли, заключается в поиске по составленным правилам совпадений (вдаваться в технические подробности здесь не будем). Одно правило = одна проблема («инцидент» в терминах SIEM). Однако по одному симптому или событию может сработать сразу несколько правил.
Принцип действия у разных вендоров одинаков, отличаются лишь некоторые детали.
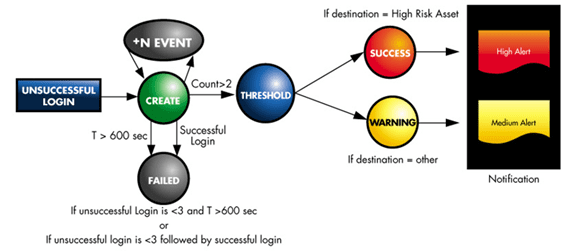
Правило имеет триггер, включающий условие, счетчик и сценарий реакции. Часть систем включают интуитивно понятные правила в графическом режиме.
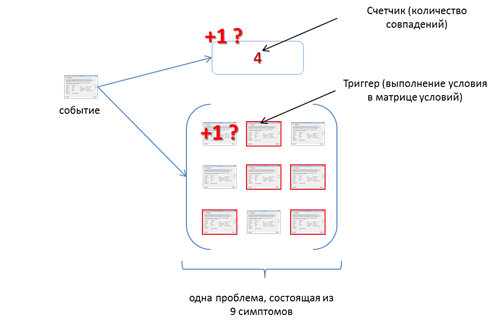
Счетчики предназначены для подсчета количества совпадений по одному и тому же правилу (симптому). Например, пять попыток неудачного входа в операционную систему от имени одной учетной записи в течение пяти минут — инцидент. С поступлением первого события о неудачной попытке входа для учетной записи запустится счетчик и триггер. Счетчик будет:
- ожидать еще четырех неуспешных попыток входа в течение 5 минут. Если эти события не поступят, то счетчик будет сброшен. Если они поступят позже с опозданием (например, с агентом не было связи), то правило снова будет запущено, а имеющееся событие будет использовано и создан инцидент.
- подсчитывать количество событий (аналогично команде t-sql – select count where …).
Триггер подобен взведенному курку пистолета. Триггер срабатывает при совпадении одного из условий правила корреляции (или в матрице – для алгоритмов). Например «(попытка неуспешного доступа) И (запуск неизвестного исполняемого файла)». В приведенном примере два симптома – попытка доступа и запуск процесса. Любое из этих событий активирует триггер, который ожидает выполнения второго критерия в промежутке времени, указанном в правиле корреляции. По истечении заданного времени триггер будет сброшен. Иначе можно получить события, связанные с инцидентами, которые давно потеряли актуальность.
Сценарий позволяет реагировать на выполнение правила. Примеры сценариев: создать инцидент во встроенном workflow в SIEM, выполнить команду, отправить электронное письмо, послать SNMP Trap. Возможность расширенного управления инцидентами в SIEM не включают, нужна интеграция с другими продуктами.
Инциденты, как было описано в предыдущих статьях, очень важны и позволяют предотвратить финансовые убытки вашей компании. Инцидент инциденту рознь. Чтобы акцентировать внимание на действительно важных и приоритетных инцидентах, используется приоритетность актива и самой проблемы. Приоритетность (или вес) назначается вручную для каждого IT-актива и является одной цифрой (1-3, 1-5) или результатом анализа параметров конфиденциальности, целостности и доступности. Эти значения используются для анализа рисков при интеграции с GRC-системами. Некоторые SIEM могут предотвращать повторную регистрацию одних и тех же событий, а также определять наличие подобных инцидентов, имеющие зависимости и связывать новый инцидент с уже открытым. Например, в системе открыт инцидент «Server # down», при этом срабатывают новые правила «Users cannot access to asset», «Multiple SYN packets to # from #».
Обычно события хранятся в течение длительного периода времени (по требованиям международных стандартов, для обеспечения доказательной базы и материала для расследования инцидентов).
Выполнять запросы к терабайтной базе данных неразумно. Поэтому, вендоры включают в правило временные рамки для триггера (глубина корреляции) или разделяют базу на онлайновую и архивную, разрешая в правилах указывать, какие данные использовать. При этом онлайновая база имеет жесткие ограничения по сроку хранения (например, сутки или неделя).
Ограничение по глубине корреляции вполне разумно и с точки зрения теории. Около 70% правил корреляции работают с событиями, которые произошли в течение суток, 20% - до одной недели, 5% - не более месяца. Оставшиеся – в интервале квартал или полгода.
Правила корреляции разбиты в SIEM на категории. Каждое правило отдельно можно включить или отключить. Практически все системы позволяют тестировать правила корреляции перед применением (рекомендую пользоваться этой возможностью). Заранее заданные правила корреляции можно использовать в качестве шаблонов для создания своих собственных.
Надеюсь, я смогла донести до вас банальную теорию. Не бойтесь корреляционных механизмов, используйте все возможности SIEM, освободите время, которое тратили на разбор тысяч событий, спасите свое зрение и автоматизируйте процесс.