Марк Райан дель Морал Талабис
Компания Secure-DNA
Содержание
- Введение
- Источники исходных данных для анализа безопасности
- Альтернативные методики из различных областей
- Средства анализа данных
- Примеры и практические руководства
- Изучение географии Интернет-атак по данным, собранным сетью-приманкой (honeypot)
- Руководство по использованию средств проекта «R» в анализе данных, собранных сетью-приманкой
- Извлечение данных о web-атаках из журналов регистрации событий Apache
- Ссылки
Введение
С появлением усовершенствованных методик сбора информации, таких
как приманки для злоумышленников, распределенные сети-приманки и
клиенты-приманки, а также блоки сбора образцов вредоносных программ,
полученные таким образом данные превратились в богатейший ресурс.
Впрочем, не стоит забывать о том, что ценность информации, в конечном
счете, напрямую зависит от эффективности методов ее анализа.
В настоящей статье описаны альтернативные методики анализа,
заимствованные из теорий статистики, искусственного интеллекта,
извлечения данных, распознавания образов при графическом проектировании
и экономики и адаптированные для решения интересующих нас задач. Кроме
того, показано, каким образом исследователи в области безопасности
могут использовать средства других дисциплин для извлечения необходимых
полезных данных. Мы надеемся, что данная работа откроет для
специалистов по безопасности всю широту и разнообразие альтернативных
методик и средств, разработанных в других дисциплинах, которые они с
успехом могут применять в своей работе. Мы будем рады, если наша статья
послужит началом совместной работы специалистов из разных областей,
которая будет направлена на изучение новых альтернативных методик,
которые могли бы быть полезны при исследованиях и анализе безопасности
систем.
Некоторые из рассматриваемых здесь методик используют алгоритмы
кластеризации для классификации атак. Рассмотрено предсказание атак с
помощью алгоритмов обучения, обнаружение атак методами искусственного
интеллекта, определение направления атак путем распознавания образов и
применение передовых методов визуализации при анализе атак.
Кроме прочего, в настоящей статье вы найдете описание уже доступных
для использования открытых средств, таких как WEKA, Tanagra и
R-Project, которые раньше не применялись для анализа безопасности
систем, но обладают огромным потенциалом в этой области.
О проекте Security Analytics
Искусство Анализа Безопасности Систем = Обеспечение Безопасности Систем + Анализ Данных
Проект Security Analytics (Искусство Анализа Безопасности Систем) – это
инициатива специалистов в области защиты данных, которая подразумевает
поиск, обнаружение и использование альтернативных методик анализа
информации по безопасности. Так как средства сбора такой информации
постоянно совершенствуются и развиваются, объем получаемых данных
растет в геометрической прогрессии. И хотя такое обилие информации в
принципе полезно, оно приводит к тому, что извлекаемые данные ценны для
нас ровно настолько, насколько ценен тот результат, который даст анализ
этих данных. Таким образом, изучение и умелое применение различных
методик анализа данных играет не менее важную роль, чем собственно сбор
этих данных. Несмотря на то, что безопасность
компьютерных систем является самостоятельной дисциплиной со своими
специфическими задачами, методики анализа данных часто могут быть
заимствованы из других областей знаний. Поэтому те специалисты, которые
ограничивают свой инструментарий рамками какой-то одной дисциплины,
неизбежно лишают себя широких возможностей, предоставляемых
разнообразными методиками, существующими за этими рамками. Возьмем, к
примеру, экономику – эта наука не смогла бы так динамично развиваться,
если бы не использовала достижения математики, психологии и
вычислительной техники. Нам кажется, что и в безопасности систем такое
возможно – используя результаты, достигнутые в других дисциплинах, мы
могли бы во много раз расширить свой потенциал. Другой важной стороной
данного проекта является идея совместной работы. Сотрудничество
специалистов по безопасности с исследователями из других областей
сейчас практически отсутствует. В то же время, специалисты по
безопасности могут работать с огромными объемами данных, а
исследователи, особенно члены научного сообщества, располагают широким
набором методик, но зачастую не имеют достаточного количества данных, к
которым их можно было бы применить. Мы надеемся создать в рамках
проекта Security Analytics форум,
на котором исследователи-теоретики и специалисты по безопасности могли
бы обмениваться данными и новыми технологиями и вести таким образом
совместную разработку методов анализа данных.
Цели исследования:
1. Определить области и дисциплины, которые могут быть полезны при исследовании безопасности систем.
2. Определить в рамках найденных дисциплин средства и методики, которые
могут быть использованы при анализе данных по безопасности.
3. Разработать форум, на котором специалисты из различных областей смогут обмениваться данными и методиками.
Источники данных при анализе безопасности
Простые приманки и сети-приманки
Приманка (honeypot) – этосредство безопасности, задача которого
состоит в том, чтобы подвергаться сканированию, атаке и взлому со
стороны злоумышленника. Существуют следующие виды приманок:
1. Приманки с высоким уровнем доступа. Такие приманки могут быть
полностью взломаны, они позволяют злоумышленнику получить полный доступ
к системе и использовать ее для дальнейших атак в сети.
2. Приманки
с низким уровнем доступа. Эти приманки имитируют работу только тех
служб, которые не могут быть использованы злоумышленником для получения
полного доступа к системе. Такие приманки предоставляют ограниченные
возможности для изучения атак, но они могут быть эффективно
использованы для получения информации об атаках на низком уровне
детализации.
Ссылки:
1. Проект Honeynet: – http://www.honeynet.org/
2. Honeyd – http://www.honeyd.org/
Блоки сбора образцов вредоносных программ
Такие модули используют осуществленные злоумышленниками атаки,
чтобы получить двоичный код, оставленный вредоносными программами во
время транзакций. Эти приманки могут предоставлять злоумышленнику как
низкий, так и высокий уровень доступа, но чаще используется именно
низкий уровень, так как целью является лишь сбор образцов вредоносных
программ.
Ссылки:
1. Nepenthes - http://nepenthes.mwcollect.org/
2. Honeybow - http://honeybow.mwcollect.org/
Клиентские приманки - Honeyclients и honeymonkeys
В то время как большинство приманок имитируют работу серверов в
пассивном ожидании того, что злоумышленник нападет на предложенную
службу, некоторые ловушки активно провоцируют злоумышленника на
осуществление атаки. В частности, если некоторым образом
скомпрометировать web-браузеры клиента, это даст возможность
вредоносным сайтам установить свои программы на компьютер жертвы. Такие
приманки постепенно просматривают web-сайты и с помощью различных
методов определяют, какие из них атакуют web-браузер. Образцы
вредоносных программ сохраняются в базе, после чего приманка очищается
от вирусов и продолжает изучение сайтов.
Ссылки:
1. Honeyclient - http://www.honeyclient.org/
2. Honeymonkey - Microsoft.com%2FHoneyMonkey%2F">http://research.microsoft.com/HoneyMonkey/
3. HoneyC - http://www.nz-honeynet.org/honeyc.html/
4. Capture-HPC - http://www.nz-honeynet.org/cabout.html/
Другие источники
Другие источники данных для анализа:
1. Спам
2. Базы данных фишинга
3. Образы дисков
4. IRC-чаты и форумы
5. Журналы регистрации
Поиск методик за пределами области безопасности систем – альтернативные подходы
Извлечение данных и текстовой информации
Извлечение данных (data mining) представляет собой процесс
автоматического поиска больших объемов информации по образцу.
Извлечение данных из текстовых массивов (text mining) – это процесс
получения ценной информации из текста.
Варианты использования:
Анализ тем обсуждений в хакерский чатах с помощью механизмов извлечения данных.
Кластеризация
Кластеризация подразумевает классификацию объектов с выделением
нескольких групп, а точнее – разделение множества данных на некоторые
подмножества (кластеры) так, чтобы данные в каждом подмножестве (в
идеальном случае) были объединены какой-то особенностью; обычно
используют степень схожести объектов на основе определенной меры
расстояния. Кластеризация данных является распространенной методикой в
статистическом анализе данных и используется во многих областях,
например, в машинном обучении, извлечении данных, распознавании
образов, анализе изображений и биоинформатике.
Варианты использования:
Классификация атак с помощью алгоритма k-средних.
Машинное обучение
Этот обширный раздел искусственного интеллекта касается
проектирования и разработки алгоритмов и методик, которые позволяют
«обучать» ЭВМ. В целом, различают два вида обучения: индуктивное и
дедуктивное. Методы индуктивного машинного обучения выделяют правила и
шаблоны на базе анализа многочисленных наборов входных данных.
Варианты использования:
Предсказание атак с помощью метода опорных векторов.
Распознавание образов
Распознавание образов решает задачи классификации данных (образов)
либо на основе априорных знаний, либо на основе статистической
информации, полученной из самих образов. Классифицируемые образы обычно
представляют собой множество результатов измерений или наблюдений,
которые могут быть представлены в виде точек в соответствующем
многомерном пространстве.
Статистика
Статистика – это математическая наука, занимающаяся сбором,
анализом, трактовкой/объяснением и представлением данных. Эта область
знаний находит применение во многих научных дисциплинах, начиная от
физики и социальных наук и заканчивая гуманитарными науками. Статистика
используется (впрочем, не всегда должным образом) при принятии решений
на основе исходной информации во всех областях бизнеса и управления.
Визуализация
К области визуализации относятся все методы создания изображений,
диаграмм или анимации при обмене сообщениями. Визуализация с самого
начала существования человечества использовалась как эффективный способ
передачи как отвлеченных понятий, так и точной информации.
Варианты использования:
Анализ осуществленных атак, составление отчетов по ним и обмен информацией.
Психология
Это научно-прикладная дисциплина, включающая изучение мыслительных
процессов и поведения человека. Специалисты в этой области занимаются
такими феноменами, как восприятие, познание, эмоции, личность,
поведение и межличностное взаимодействие. Кроме того, психологи изучают
возможности практического применения этой теории в различных сферах
деятельности человека, например, при решении каждодневных личных
проблем или лечении психических заболеваний.
Варианты использования:
Изучение мотиваций злоумышленников через хакерские IRC-чаты.
Экономика
Экономика – это социальная наука, изучающая производство,
распределение и потребление товаров и услуг. Термин «экономика»
образован от греческих слов οἶκος (oikos – дом) and νόμος (nomos –
обычай или закон) и дословно переводится как «искусство ведения
домашнего хозяйства».
Варианты использования:
Теория игр и изучение поведения взломщиков
Средства анализа данных
Weka
URL: http://www.cs.waikato.ac.nz/ml/weka/
Области использования:
1. Извлечение знаний
2. Извлечение текстовых данных
3. Кластеризация
4. Машинное обучение
Weka – это библиотека алгоритмов машинного обучения для задач
извлечения данных. Эти алгоритмы можно либо напрямую применить к набору
данных, либо использовать их вызов в Java-коде. Библиотека Weka
содержит средства для предварительной обработки данных, правила
классификации, регрессии, кластеризации и связывания, а также
инструменты визуализации. Кроме того, эта библиотека предоставляет
широкие возможности для разработки новых схем машинного обучения.
Tanagra
URL: http://eric.univ-lyon2.fr/~ricco/tanagra/en/tanagra.html/
Области использования:
1. Извлечение знаний
2. Извлечение текстовых данных
3. Кластеризация
4. Машинное обучение
Tanagra – это свободно распространяемое программное обеспечение для
извлечения знаний, используемое при решении научных и исследовательских
задач. Tanagra содержит различные методы извлечения данных, взятые из
областей исследовательского анализа данных, статистического обучения,
машинного обучения и теории баз данных.
R-Project
URL: http://www.r-project.org/
Области использования:
1. Статистика
2. Извлечение знаний
3. Извлечение текстовых данных
4. Кластеризация
5. Машинное обучение
6. Распознавание образов
«R» – это язык и среда для выполнения статистических расчетов и
построения графиков. Это один из проектов GNU (GNU is Not Unix),
аналогичный языку и среде «S», которые были разработаны в Bell
Laboatories (Lucent Technologies, предыдущее название - AT&T)
Джоном Чамберсом (John Chambers) и его коллегами. «R» можно даже
рассматривать как новую реализацию среды «S». Хотя между проектами есть
существенные различия, большая часть кода, написанного для «S», была
без изменений перенесена в «R».
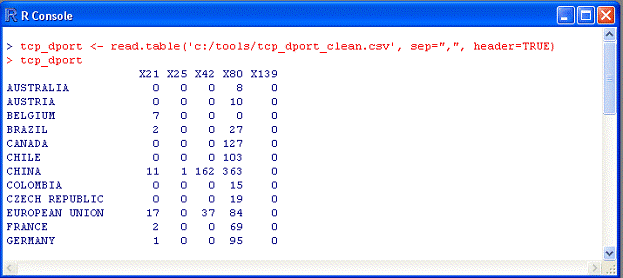
Рис. 1
Flowtag
URL: http://r82h147.res.gatech.edu/pages/research/projects.html/
Область использования:
1. Визуализация
Flowtag представляет собой средство для совместного анализа атак и обмена информацией о них специалистами по безопасности.
Рис. 2
Honeysnap
URL: http://www.ukhoneynet.org/tools/honeysnap/
Области использования:
1. Предварительная обработка данных
2. Фильтрация данных
Honeysnap был разработан как средство типа «командная строка» для
первичного анализа одиночных pcap-файлов и их наборов с последующей
выдачей отчетов о важных событиях, обнаруженных в проанализированном
массиве данных. Такие отчеты содержат анализ безопасности системы с
подготовленным меню важной сетевой активностью; использование данного
инструмента направлено на подготовку материалов для дальнейшего
«ручного» анализа и позволяет значительно сократить время изучения
событий.
Excel и Access
URL: http://office.microsoft.com/en-us/default.aspx/
Области использования:
1. Предварительная обработка данных
2. Фильтрация данных
3. Статистика
Популярнейшие табличные интерактивные базы данных от Microsoft.
Orange
URL: http://www.ailab.si/orange/
Области использования:
1. Извлечение знаний
2. Извлечение текстовых данных
3. Кластеризация
4. Машинное обучение
Orange – это многокомпонентная оболочка, которая позволяет создавать
собственные компоненты на основе уже имеющихся. Вы можете даже создать
прототипы своих компонент в среде Python и использовать их вместо
некоторых стандартных C-компонент в оболочке Orange. Например, можно
написать собственную функцию для оценки некоторых атрибутов и
использовать ее в дереве индуктивного алгоритма классификации Orange.
Рис. 3
Методики
Итак, перечень описанных выше «полезных» методик выглядит следующим образом:
1. Предварительная обработка данных
2. Фильтрация данных
3. Обнаружение атак
4. Классификация атак
5. Образцы и направления атак
6. Предсказание атак
7. Мотивации и поведение злоумышленников
Соответствие дисциплин и методик
Методики |
Дисциплины |
Примеры инструментов |
Предварительная обработка и фильтрация данных |
Кластеризация данных и извлечение текстовых данных |
Honeysnap
Excel
Access |
Обнаружение атак |
Визуализация
Извлечение знаний и текстовых данных |
Flowtag
R-Project
Orange |
Классификация атак |
Кластеризация
Обучающие алгоритмы |
Weka
Tanagra
Orange
PyCluster |
Образцы и направления атак |
Статистика
Визуализация
Извлечение знаний и текстовых данных |
R-Project
Orange |
Предсказание атак |
Статистика
Обучающие алгоритмы |
R-Project |
Мотивации и поведение злоумышленников |
Психология
Экономика
Извлечение знаний и текстовых данных |
R-Project
Weka |
Изучение географии Интернет-атак с помощью данных, собранных сетью-приманкой
Использование анализа основных компонент при изучении образцов атак
Краткие характеристики эксперимента:
Использовались данные, собранные приманкой за 1 месяц
Рассматривались 5 базовых портов (21, 25, 42, 80, 139)
Применялись методики гистограмм и анализа основных компонент
В качестве инструментария был взят «R» (R-Project)
Предполагаемые направления развития: использование изменяющихся данных,
рассмотрение большего числа портов, внедрение новых методик
Результаты и выводы
Географическое распределение источников атак направленных на пять базовых портов
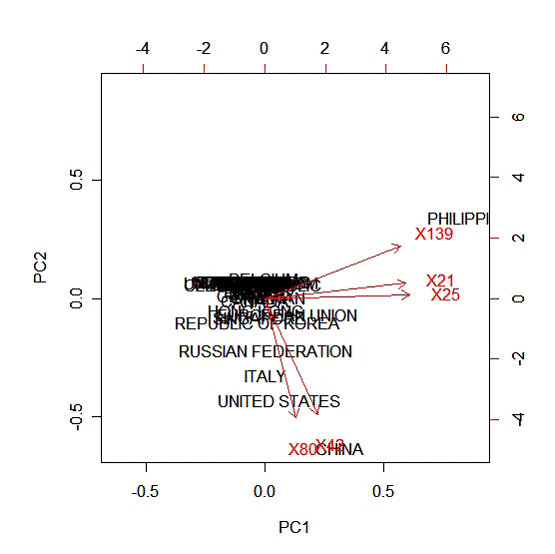
Рис. 4
Выводы:
1. Порты 21, 25 и 129 в большой степени взаимосвязаны между собой.
2. Порты 42 и 80 в большой степени взаимосвязаны друг с другом.
3. Атаки, осуществленные с Филиппин, были в основном направлены на порты 21, 25 и 139.
4. Атаки, осуществленные из Китая, США, Италии, России и Республики Корея, были в основном направлены на порты 21, 25 и 139.
Географическое распределение атак на порты 42 и 80
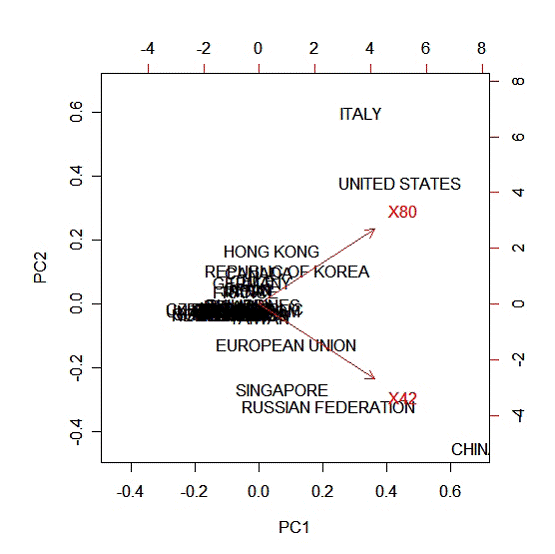
Рис. 5
1. Атаки на порты 42 и 80 напрямую связаны друг с другом.
2. Атаки на порт 80 больше распространены в Италии, США, Гонконге и Республике Корея.
3. Атаки на порт 42 больше распространены в Китае, России, Сингапуре и Евросоюзе.
4. В остальных странах атаки распределены между портами практически поровну.
Распределение атак на порт 80
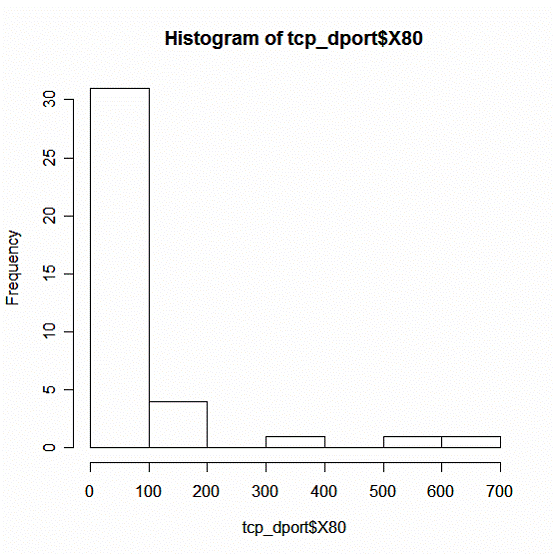
Рис. 6
Выводы:
1. Число атак на порт 80 варьируется в пределах от 0 до 700 на одну страну.
2. Интенсивность в интервале от 0 до 100 атак наиболее характерна для большинства стран.
Распределение атак на порт 42
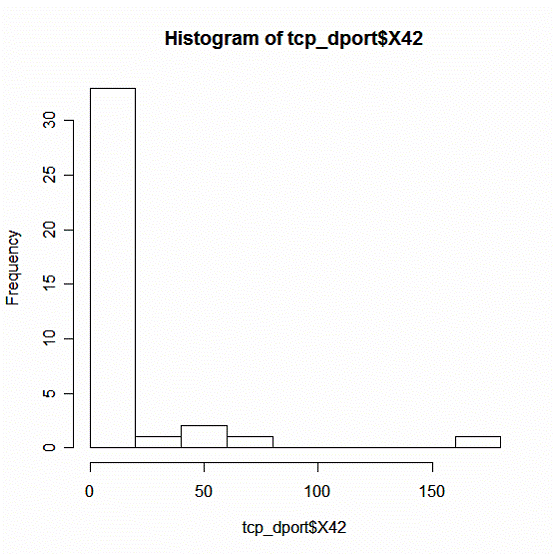
Рис. 7
Выводы:
1. Число атак на порт 42 варьируется в пределах от 0 до 150 на одну страну.
2. Интенсивность в интервале от 0 до 20 атак наиболее характерна для большинства стран.
Географическое распределение источников атак на порты 21, 25 и 139
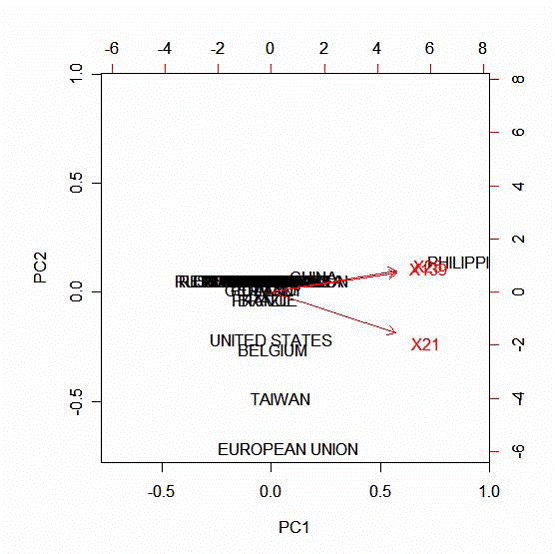
Рис. 8
Выводы:
1. Порты 21, 25 и 139 напрямую связаны между собой.
2. Порты 25 и 139 связаны друг с другом сильнее, чем с портом 21.
3. Атаки на порты 25 и 139 в основном осуществляются с Филиппин.
4. Атаки на порт 21 в основном осуществляются из Евросоюза, Тайваня, Бельгии и США.
Географическое распределение атак на порты 21 и 25
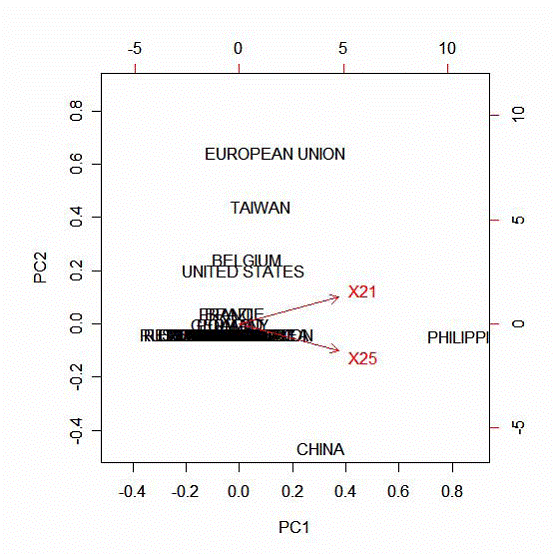
Рис. 9
Выводы:
1. Порты 21 и 25 напрямую связаны между собой.
2. Наиболее часто атаки на порты 21 и 25 встречаются на Филиппинах,
причем интенсивность атак распределена между этими портами практически
поровну.
3. В Китае чаще происходят атаки на порт 25, а в Евросоюзе, Тайване, Бельгии и США – на порт 21.
Распределение атак на порт 25
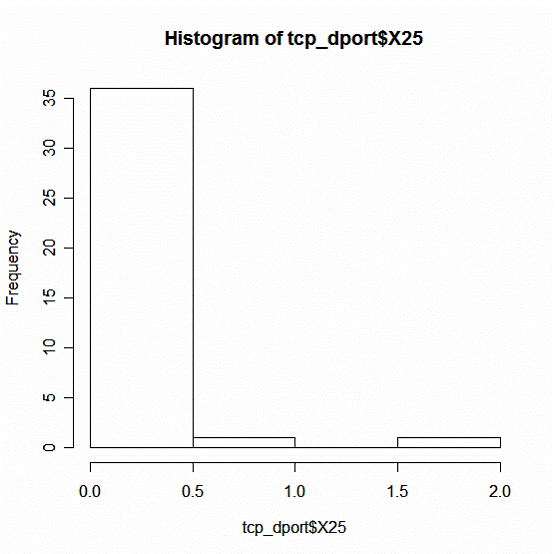
Рис. 10
Выводы:
1. Число атак на порт 25 варьируется в пределах от 0 до 2 на одну страну.
2. Среди всех стран наиболее распространена интенсивность в диапазоне от 0 до 1 атаки.
Распределение атак на порт 139
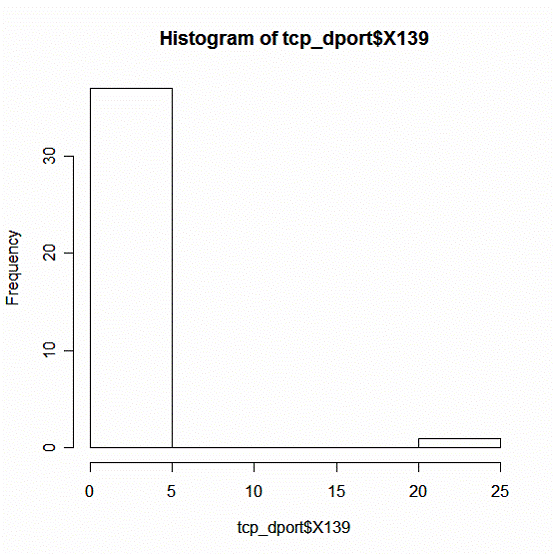
Рис. 11
Выводы:
1. Число атак на порт 139 варьируется в пределах от 0 до 25 на одну страну.
2. Среди всех стран наиболее распространена интенсивность в диапазоне от 0 до 5 атак.
Распределение атак на порт 21
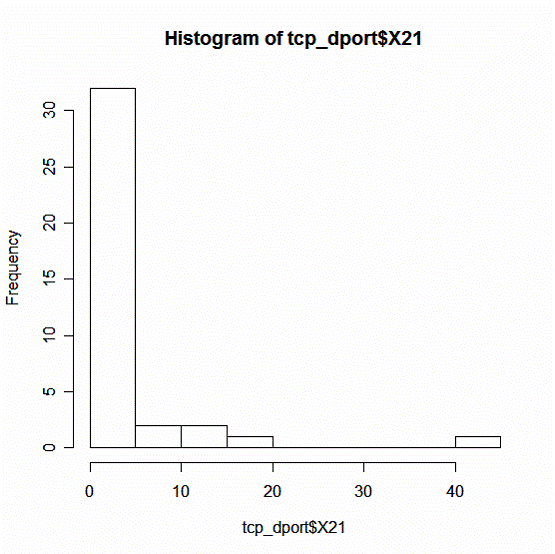
Рис. 12
Выводы:
1. Число атак на порт 21 варьируется в пределах от 0 до 40 на одну страну.
2. Среди всех стран наиболее распространена интенсивность в диапазоне от 0 до 5 атак.
Руководство по использованию инструментария «R» при анализе данных по безопасности
Обучающее руководство по анализу безопасности
Шаг 1: Данные
В нашем случае в качестве исходных данных были взяты pcap-файлы из
локальной сети-приманки. Так как в настоящем исследовании не имеет
принципиального значения то, какой инструмент анализа выбрать, автор
воспользовался привычным для него средством – Snort.
Pcap-файлы были получены из сети-приманки и затем обработаны Snort в
режиме проверки текущего состояния с занесением всех (даже абсолютно
неподозрительных) пакетов в базу данных (возможно, существуют более
эффективные способы выполнения этой операции).
После этого мы получили следующую базу данных Snort, содержащую такие
поля, как порты назначения, порты источника, IP-адрес и сигнатуры:
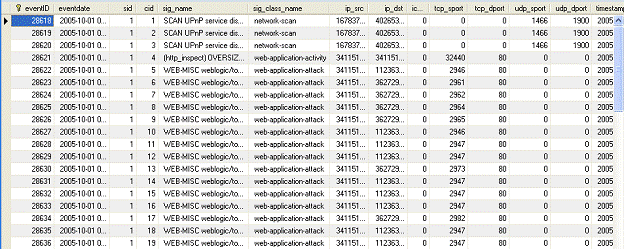
Рис. 13
Шаг 2: Предварительная обработка
Очевидно, что действия, выполняемые на данном этапе, могут быть разными
в зависимости от того, какие цели ставит перед собой исследователь. В
данном случае нас интересовало общее число атак на порт назначения со
стороны каждого IP-адреса источника. Был написан (и помещен на
внутренний сервер) сценарий, который обрабатывал данные и сохранял их в
CSV-файл. Таким образом, мы получили следующий CSV-файл с именем
tcp_dport_clean:
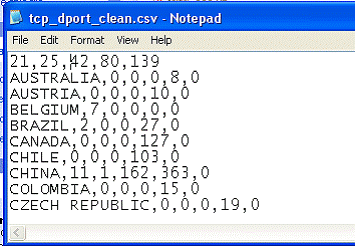
Рис. 14
Обратите внимание на то, что первая строка короче других на один
столбец; это объясняется тем, что страны являются признаком
классификации, а не переменной, подлежащей вычислению.
Шаг 3: Запуск «R»
Итак, мы получили файл данных. После этого необходимо запустить проект
«R». «R» – это язык и среда для выполнения статистических расчетов и
построения графиков. Здесь исследователю предлагается широкий и гибкий
набор статистических алгоритмов и методов построения графиков. Среда
запускается под операционными системами Linux, MacOS и Windows. Установочный файл можно скачать на http://www.r-project.org/.
При выполнении настоящего исследования среда «R» запускалась под
операционной системой Windows, поэтому при использовании операционных
систем MacOS или Linux Вы, возможно, заметите небольшие отличия в
интерфейсе. Итак, начальное окно программы выглядит следующим образом:

Рис. 15
Если Вы работаете в среде «R» впервые, при необходимости воспользуйтесь следующими командами:
- help.start()
- help([имя функции])
- help.search([строка-запрос])
- demo([имя функции])
- example([имя функции])
Например, посмотрите, как можно использовать один из встроенных наборов данных:
example(swiss)
Выполнение этой команды даст следующий результат:
Рис. 16
Шаг 4: Загрузка данных
После того, как Вы изучите интерфейс среды, можно приступать к загрузке
данных. На шаге 2 нами после предварительной обработки был создан файл
данных; мы назвали этот файл tcp_dport_clean.csv. Для того, чтобы
теперь загрузить этот файл в среду «R», воспользуемся командой
read.table(), которая считывает файл в табличном формате и преобразует
его в кадр данных. В ходе настоящего эксперимента эта команда была
использована следующим образом:
tcp_dport <- read.table('c:/tools/tcp_dport_clean.csv', sep=",", header=TRUE)
Здесь «tcp_dport» – это имя создаваемого кадра данных либо объекта
данных, к которому среда будет обращаться при выполнении Вами
каких-либо операций с данными. Далее указывается адрес папки и имя
исходного файла данных, затем следует разделитель (в данном случае
запятая, sep=","), и, наконец, флаг, информирующий среду о том, что в
файле данных присутствует заголовок (header=TRUE).
Чтобы просмотреть загруженные данные, просто введите имя кадра данных. В нашем случае – «tcp_dport»
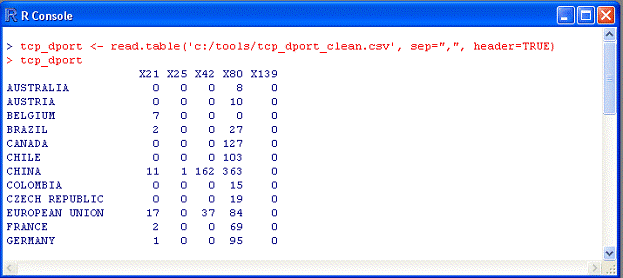
Рис. 17
После того, как данные загружены в среду «R», мы можем выполнить над ними различные действия.
Шаг 5: Выбор и применение инструментов
Вне зависимости от того, каковы цели Вашего исследования, в среде «R»
Вы найдете множество подходящих статистических методов и алгоритмов
извлечения данных. В рассматриваемом случае необходимо было провести
анализ основных компонент, изучить взаимосвязи между ними и построить
соответствующие гистограммы.
Простейший способ выполнить поставленные задачи состоит в том, чтобы
вывести на диаграмму все имеющиеся данные. Это можно осуществить путем
вызова команды plot(), которая представляет собой групповую функцию для
построения графиков R-объектов:
plot(tcp_dport)
Результатом выполнения такой команды будет следующая диаграмма:
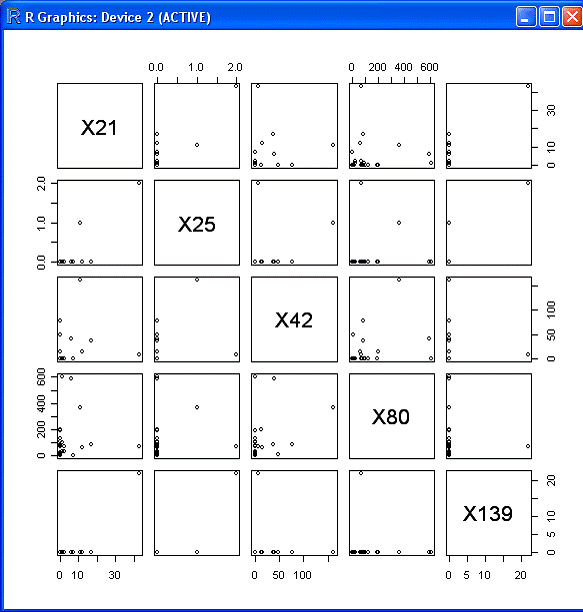
Рис. 18
Однако такая форма неудобна и мало полезна.
Для получения более информативных результатов обратимся к анализу
основных компонентов данных. Анализ основных компонентов – это
методика, направленная на упрощение входных наборов данных путем
уменьшения размерности пространства, в котором эти наборы
рассматриваются. Такой анализ выполняется посредством команды prcomp().
Чтобы представить полученные результаты в наглядной форме, обычно
используется команда biplot(). Biplot (двойная диаграмма) – это
диаграмма, на которой одновременно представлены как результаты
наблюдений, так и переменные матрицы многомерных данных. Не углубляясь
в дальнейшие подробности, покажем, как описанные команды были
использованы в настоящем исследовании:
biplot(prcomp(tcp_dport, scale=T), expand=T, scale=T)
По существу, выполнение этого выражения состоит в проведении
анализа основных компонент данных и представлении результатов анализа в
графической форме. Масштаб (scale) и параметры развертки (expand)
используются для настройки координатной сетки. Результат выполнения
выражения приведен ниже:
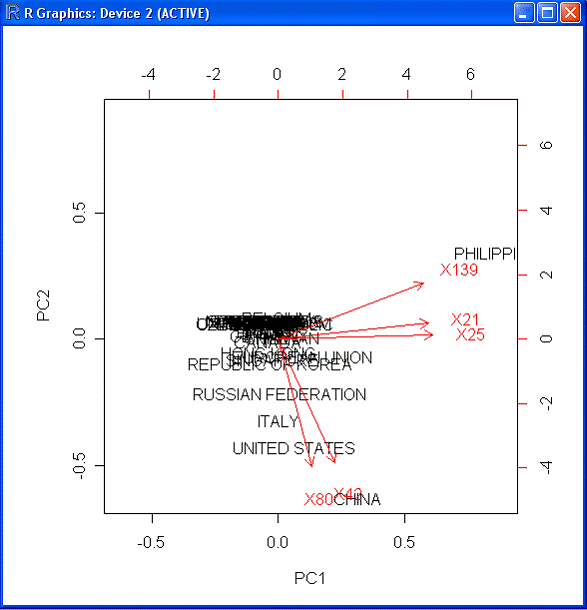
Рис. 19
При необходимости конкретизации результатов, например, чтобы
исследовать только порты 21 и 25, можно воспользоваться следующим
выражением:
biplot(prcomp(tcp_dport[1:2], scale=T), expand=T, scale=T)
Здесь подразумевается, что порты 21 и 25 соответствуют столбцам 1 и 2 (запись «[1:2]» в команде).

Рис. 20
Теперь рассмотрим взаимосвязь компонентов, воспользовавшись командой cor():
cor(tcp_dport)
Результатом ее выполнения будет следующая таблица:
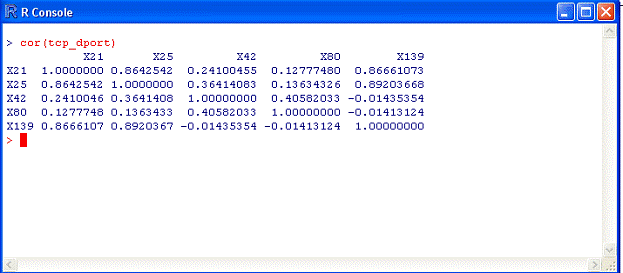
Рис. 21
Здесь наглядно показана взаимосвязь различных портов в рассматриваемом
наборе данных. Далее, построим несколько гистограмм с помощью команды
hist().
hist(tcp_dport$X80)
Здесь tcp_dport – это имя объекта данных, а X80 – имя поля. Таким образом, получаем следующую гистограмму для порта 80:
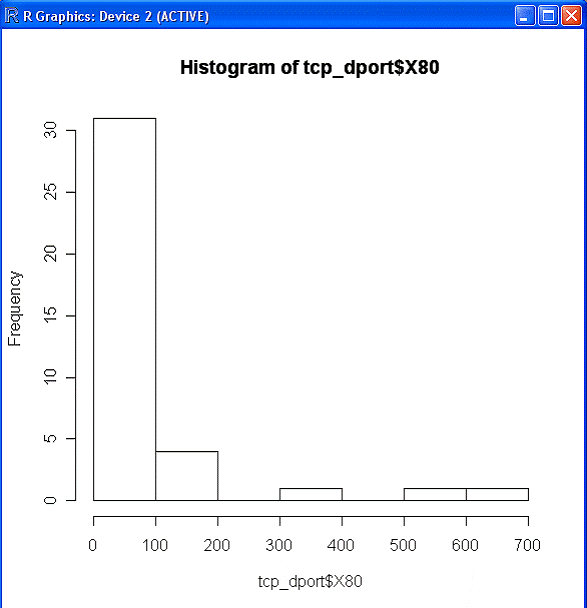
Рис. 22
Не правда ли, такие графики очень наглядны? Среда «R» позволяет
выполнить множество других операций, например, кластеризацию и анализ с
помощью временных рядов. Рассмотрению этих функций автор намеревается
посвятить следующую работу.
Полностью результаты анализа доступны на внутреннем сервере в
разделе DA. Для более подробного изучения рассмотренных методик
воспользуйтесь R-командами help() и help.search() – они часто бывают
очень полезны.
Извлечение данных о web-атаках из журналов регистрации событий Apache
Использование алгоритмов извлечения данных для классификации web-атак
В настоящее время автор исследует возможность применения методики
автоматической классификации текстов для анализа записей в журналах
регистрации событий Apache. Замысел состоит в том, чтобы автоматически
классифицировать содержимое журналов для постоянного отслеживания атак.
Результаты:
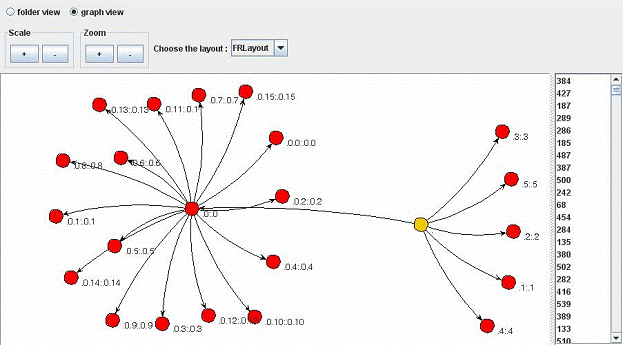
- Группа 0.1:0.1
a. awstats.pl
b. configdir
c. libsh
d. ping
e. perl
f. temp2006
- Группа 0.2:0.2
a. index.php
b. option
c. com_content
d. do_pdf
e. index2.php
f. _REQUEST[option]
g. com_content _REQUEST[Itemid]
h. GLOBALS
i. mosConfig_absolute_path
j. cmd.gif
k. giculz
l. mambo
- Группа 0.3:0.3
a. cache
b. index2.php
c. _REQUEST[option]
d. com_content _REQUEST[Itemid]
e. GLOBALS
f. mosConfig_absolute_path
g. cmd.gif
h. giculz
- Группа 0.4:04
a. index2.php
b. option
c. com_content
d. do_pdf
e. index2.php
f. _REQUEST[option]
g. com_content _REQUEST[Itemid]
h. GLOBALS
i. mosConfig_absolute_path
j. cmd.gif
k. sexy
- Группа 0.5:0.5
a. awstats
b. awstats.pl
c. configdir
d. killok
e. cgi-bin
- Группа 0.6:0.6
a. cvs
b. index2.php
c. _REQUEST[option]
d. com_content _REQUEST[Itemid]
e. GLOBALS
f. mosConfig_absolute_path
g. aldoilea.info
h. cmd.txt
i. cback
j. mambo
- Группа 0.7:0.7
a. modules
b. Forums
c. admin
d. admin_styles.php
e. phpbb_root_path
f. cmd.gif
g. criman
- Группа 0.8:0.8
a. mambo
b. index2.php
c. _REQUEST[option]
d. com_content
e. _REQUEST[Itemid]
f. GLOBALS
g. mosConfig_absolute_path
h. cmd.gif
i. bash
- Группа 0.9:0.9
a. cgi-bin
b. awstats.pl
c. configdir
d. killoz
- Группа 0.10:0.10
a. cgi-bin
b. awstats.pl
c. configdir
d. killos
e. listen
- Группа 0.11:0.11
a. modules
b. coppermine
c. themes
d. default
e. theme.php
f. THEME_DIR
g. cmd.gif
h. cbac
- Группа 0.13:0.13
a. cvs
b. index.php
c. _REQUEST[option]
d. com_content _REQUEST[Itemid]
e. GLOBALS
f. mosConfig_absolute_path
g. cmd.gif
h. cacti
i. cgi-bin
j. awstats
k. awstats.pl
l. configdir
m. phpBB2
n. admin_styles.php
o. phpbb_root_path
p. modules
q. Forums
r. mambo
s. index.php
t. _REQUEST[option]
u. com_content _REQUEST[Itemid]
v. GLOBALS
w. mosConfig_absolute_path
- Группа 0.14:0.14
a. cgi-bin
b. awstats.pl
c. configdir
d. echo
e. b_exp
f. uname
g. E_exp
- Группа 0.15:0.15
a. cgi-bin
b. awstats
c. awstats.pl
d. configdir
e. nikons
- Группа 1:1
a. < name>< value>< param>< params>< methodCall>
b. perl dc.txt
c. cback
- Группа 2:2
a. zboard
b. botperl
c. error.php
d. zeroboard
e. bbs
f. skin zero_vote
g. kaero
h. fbi.gif
- Группа 3:3
a. modules
b. PNphpBB2
c. includes
d. functions_admin.php
e. haita
f. cmd.dat
- Группа 4:4
a. webcalendar
b. send_reminders.php
c. includedir
d. haita
e. tools
f. cmd.dat

Группа 1:
Атака awstats с ключевыми словами "ping" и "perl"
Группа 2:
Типичная атака mambo mosConfig_absolute_path с "giculz"
Группа 3:
Аналогично группе 2, но включая слово "cache"
Группа 4:
Аналогично группе 2, но со словом "sexy"
Группа 5:
Атака awstats с "killok"
Группа 6:
Распространенные ключевые слова, включая cvs, mosConfig_absolute_path,
aldoilea.info, cback, mambo. "aldoilea.info" и "cback"
Группа 7:
Атаки phpbb с "criman"
Группа 8:
mambo с "bash"
Группа 9:
awstats с "killoz"
Группа 10:
awstats с "killos" и "listen"
Группа 11:
coppermine, theme.php и THEME_DIR с "cbac"
Группа 12:
"cacti" и связанные с ним, включая phpbb2, awstats и mambo
Группа 13:
awstats с "b_exp", "uname", "E_exp"
Группа 14:
awstats с "nikons"
Группа 15:
"< name>< value>< param>< params>< methodCall>" с "perl dc.txt" и "cback"
Группа 16:
zeroboard / zboard / bbs с "kaero" и "fbi.gif"
Группа 17:
PNphpBB2 с "haita"
Группа 18:
webcalendar и send_reminders.php с "haita"
Ссылки:
Honeynet Project
http://www.honeynet.org
Honeyd
http://www.honeyd.org
Nepenthes
http://nepenthes.mwcollect.org/
HoneyBow
http://honeybow.mwcollect.org/
Honeyclient
http://www.honeyclient.org/
Strider Project
http://research.microsoft.com/HoneyMonkey/
HoneyC
http://www.nz-honeynet.org/honeyc.html
Capture-HPC
http://www.nz-honeynet.org/cabout.html
Weka
http://www.cs.waikato.ac.nz/ml/weka/
Tanagra
http://eric.univ-lyon2.fr/~ricco/tanagra/en/tanagra.html
R-Project
http://www.r-project.org/
FlowTag
http://r82h147.res.gatech.edu/pages/research/projects.html
Honeysnap
http://www.ukhoneynet.org/tools/honeysnap/
Excel and Access
http://office.microsoft.com/en-us/default.aspx
Orange
http://www.ailab.si/orange
|